


Α. Ονειρεύεται η Τεχνητή Νοημοσύνη ανθρώπινους συνομιλητές;
Στο γνωστό μυθιστόρημα του Ουμπέρτο Έκο «Το Εκκρεμές του Φουκώ» οι τρεις πρωταγωνιστές «συνδιαλέγονται» με έναν πρωτόγονο για τα σημερινά δεδομένα ηλεκτρονικό υπολογιστή, χρησιμοποιώντας την Basic γλώσσα προγραμματισμού. Τον τροφοδοτούν με διάφορα δεδομένα που αντλούν από τα μυστικιστικά βιβλία που διαβάζουν και θεωρούν ότι ο Αμπουλάφια (το όνομα που έδωσαν στον υπολογιστή) θα τους δώσει το πραγματικό όνομα του Θεού. Ο διάλογος με την μηχανή αποκτά γι’ αυτούς μια μεταφυσική διάσταση, ταυτόχρονα με μια παιδική αφέλεια και ενθουσιασμό.
«Τελεία και πάει μόνο του στην αρχή. Δοκιμή δοκιμή δοκιμή παρακαλώ παρακαλώ, με το κατάλληλο πρόγραμμα κάνεις και αναγραμματισμούς, αν γράψεις ένα ολόκληρο μυθιστόρημα για έναν ήρωα του Νότου που λέγεται Ρετ Μπάτλερ και μια ιδιότροπη κοπέλα που λέγεται Σκάρλετ, κι έπειτα μετανιώσεις, δεν έχεις παρά να δώσεις διαταγή και ο Αμπού μετατρέπει όλους τους Ρετ Μπάτλερ σε πρίγκιπα Αντρέι, τις Σκάρλετ σε Νατάσα, την Ατλάντα σε Μόσχα, και έχεις γράψει το Πόλεμος και Ειρήνη.»[1]
Η συνομιλία του ανθρώπου με την Τεχνητή Νοημοσύνη (εφεξής ΤΝ) δεν αποτελεί από μόνη της μια καινοτομία του ψηφιακού καπιταλισμού, αλλά η εξέλιξή της διαρκεί δεκαετίες τώρα. Ας φανταστούμε όμως ότι συνδιαλεγόμαστε με έναν συνομιλητή, ο οποίος φαινομενικά γνωρίζει τα πάντα ή έχει άποψη επί παντός επιστητού. Έχει απαντήσεις σχεδόν για κάθε ερώτηση που κάνουμε και για κάθε τι που αναζητούμε. Σε αυτά που δεν γνωρίζει ακριβώς τι να αποκριθεί, δίνει μεσοβέζικες και μετριοπαθείς απαντήσεις, φαινομενικά αντικειμενικές, αλλά ουσιαστικά και πάλι μεροληπτικές. Μέχρι τις 30 Νοεμβρίου 2022 οι περισσότεροι θα αναγνώριζαν στην παραπάνω περιγραφή την μηχανή αναζήτησης της Google, την ψηφιακή εγκυκλοπαίδεια Wikipedia ή ακόμα και την Alexa της Amazon. Αυτή είναι και η ημερομηνία που κυκλοφορεί και για δημόσια χρήση το ChatGPT (Chat Generative Pre-Trained Transformer) της OpenAI, μία μηχανής τεχνητής νοημοσύνης, με σκοπό την κατά το δυνατό καλύτερη μίμηση της ανθρώπινης συνομιλίας (chatbot). Το ChatGPT έρχεται να προστεθεί σε μια σειρά μηχανών τεχνητής νοημοσύνης, οι οποίες αποτελούν και τη νέα εμμονή των προγραμματιστών (αλλά κυρίως των επενδυτών) της Silicon Valley. Προηγήθηκαν άλλωστε εφαρμογές όπως το Midjourney, το Dall-E και το Stable Diffusion, οι οποίες επεξεργάζονται δισεκατομμύρια εικόνες, ώστε να δίνουν την δυνατότητα στους χρήστες τους να παράγουν «έργα τέχνης» μέσω γραπτών εντολών, συνδυάζοντας με απρόσμενους και ευρηματικούς ομολογουμένως τρόπους τα υπάρχοντα δεδομένα που οι προγραμματιστές τους φρόντισαν να τους προμηθεύσουν.

Το μειονέκτημα όλων αυτών των μηχανών είναι ακριβώς ότι περιορίζονται ακριβώς από τα δεδομένα πάνω στα οποία εκπαιδεύτηκαν, ακόμα αν και αυτά για τον άνθρωπο φαντάζουν κυριολεκτικά άπειρα. Στην περίπτωση της Google προμοτάρονται αποτελέσματα αναλόγως με την δημοφιλία τους ή με το πόσο έχει πληρώσει κάποιος ιδιώτης ή εταιρεία, ώστε να βγαίνει πιο πάνω στα αποτελέσματα. Ο χρήστης των μηχανών αναζήτησης δύναται να επιλέξει μέσα από εκατοντάδες ή ακόμα και χιλιάδες αποτελέσματα και έχει την τελευταία λέξη για την πηγή που θα χρησιμοποιήσει. Αντίθετα, στην περίπτωση του ChatGPT, οι απαντήσεις στις κάθε λογής αναζητήσεις έρχονται ως «παγιωμένες» και ο χρήστης δεν έχει το δικαίωμα επιλογής, ούτε συνήθως μπορεί να δει τις πηγές που χρησιμοποιήθηκαν. Έχει ωστόσο την επιλογή του να δει παραλλαγές των απαντήσεων κλικάροντας, να αποκτήσει δηλαδή την απάντηση που θα τον ικανοποιήσει, στην επιλογή regenerate response. Επεμβαίνει και εκμαιεύει την απάντηση, με τρόπο που πιθανότατα θα προσέβαλε τον ανθρώπινο συνομιλητή του σε μια αντίστοιχη περίσταση ή ακόμα χειρότερα θα θύμιζε σκηνή ανάκρισης σε κάποια Χολιγουντιανή ταινία.
Ο ιστορικός Jonathan Crary στο βιβλίο του Scorched Earth (μτφ. Καμένη Γη) σκιαγραφεί μια δυστοπική και απαισιόδοξη εικόνα του ψηφιακού καπιταλισμού, ο οποίος αποτελεί, όπως μας εξηγεί, μια παγκόσμια οικονομία που λειτουργεί 24/7 εξαντλώντας πόρους του πλανήτη και παρεισφρέοντας σε κάθε πτυχή του ανθρώπινου βίου, απορρυθμίζει και θρυμματίζει τις συλλογικότητες. Το υποκείμενο έχει μεν την δυνατότητα να εντάσσεται σε ολοένα και πιο ευρείες ψηφιακές κοινότητες, οι οποίες όμως συμμορφώνονται απόλυτα σε ένα μονοπώλιο πληροφορίας, που ελέγχεται από τις καπιταλιστικές ελίτ.[2] Με παρόμοιο τρόπο και η πληροφορία που μας προσφέρει η μηχανή, οι απαντήσεις του ChatGPT, έρχονται διαμεσολαβημένες από τις επιλογές των ίδιων των προγραμματιστών. Τι συμβαίνει όμως, όταν ο αλγόριθμος μέσω των απαντήσεων του διασπείρει fake news, προκαταλήψεις, στερεότυπα, ρατσιστικές αντιλήψεις και ψευδοεπιστημονικές-συνωμοσιολογικές θεωρίες; Πόσο επισφαλής γίνεται η έρευνα και πόσο δυσχεραίνει το έργο της ακαδημαϊκής κοινότητας, έχοντας απέναντι της ένα κοινό (φοιτητές, αναγνώστες, ασθενείς) που θα εμπιστευτεί περισσότερο την ψυχρή λογική του αλγορίθμου παρά την επιρρεπή σε σφάλματα ανθρώπινη;
Στον αντίποδα, σε μια περισσότερο αισιόδοξη και λιγότερο δυστοπική πρόβλεψη στα μέσα της προηγούμενης δεκαετίας, ο Ray Kurzweil, Διευθυντής Μηχανικών της Google και επομένως και μέλος της καπιταλιστικής ελίτ, βλέπει θετικά την εξέλιξη της τεχνητής νοημοσύνης η οποία θεωρεί πως τελεολογικά θα οδηγήσει στην συγχώνευση ανθρώπινης και τεχνητής νοημοσύνης και στην ψηφιακή «αθανασία». Η ψηφιακή εξέλιξη συναντά την εξέλιξη του ίδιου Homo Sapiens και πιστεύει ότι μέχρι το 2029 η τεχνητή νοημοσύνη θα περάσει το Turing test και θα φτάσει στα επίπεδα της ανθρώπινης μέχρι να την ξεπεράσει και τελικά να συγχωνευτεί μαζί της, οδηγώντας σε μια μετα-ανθρώπινη μοναδικότητα (Singularity).
Μια τέτοια εξέλιξη παρουσίασε και η τηλεοπτική σειρά Black Mirror στο επεισόδιο San Junipero, ώστε να μπορεί το ανθρώπινο είδος να ζει σε έναν εικονικό παράδεισο, με τις αναμνήσεις του και όλες τις εγκεφαλικές του λειτουργίες μεταφορτωμένες σε ένα ψηφιακό περιβάλλον. Σε δοκίμιο-κριτική πάνω σε αυτό το επεισόδιο η Βασιλική Λαλιώτη και ο Μανώλης Πατηνιώτης αναφέρουν σχετικά με την ψηφιακή δυνητικότητα και τον μετα-άνθρωπο ότι «υπό το πρίσμα μιας κριτικής προσέγγισης όμως αυτό που έχει σημασία είναι ότι, ανάμεσα στην αφελή αισιοδοξία της ψηφιακής αυτοπραγμάτωσης και την τεχνοφοβική απαισιοδοξία της ψηφιακής κόλασης, μοιάζει να ξεδιπλώνεται ένα νέο πεδίο ανθρώπινης επιτελεστικότητας. Η ανάδυση της ψηφιακής δυνητικότητας υπόσχεται έναν ριζικό επαναπροσδιορισμό των τρόπων με τους οποίους τα υποκείμενα αντιλαμβάνονται και πραγματώνουν τους εαυτούς τους[…] Η έκβαση αυτής της διαδικασίας δεν είναι δεδομένη».[3]
Β. Η Τεχνητή Νοημοσύνη μαθαίνει γράμματα σπουδάγματα στο Κρυφό Σχολειό
Πολλά άρθρα μπορεί να βρει κανείς πάνω στις δυνατότητες, αλλά και στους περιορισμούς ενός chatbot, το οποίο μιμείται την ανθρώπινη σκέψη και ομιλία. Αρκετοί μάλιστα έσπευσαν να χαιρετήσουν τη χρήση του ως εκπαιδευτικό εργαλείο. Φοιτητές εντόπισαν και τη χρήση του ως «βοηθoύ» στην εξεταστική, αφού φαίνεται να πέρασε με επιτυχία εξετάσεις πανεπιστημιακού επιπέδου. Τι συμβαίνει όμως, όταν, για παράδειγμα, θέσει κάποιος στο chatGPT ερωτήσεις σχετικές με την ελληνική ιστορία που αφορούν είτε ιστορικούς μύθους, είτε και ιστορικά αφηγήματα που έχουν απασχολήσει την ακαδημαϊκή κοινότητα των ιστορικών, αλλά και την δημόσια ιστορία, διαδραματίζοντας κομβικό ρόλο στην διαμόρφωση της ιστορικής κουλτούρας; Η πρώτη ερώτηση που του θέσαμε αφορά το «Κρυφό Σχολειό», έναν από τους πιο γνωστούς και επίμονους μύθους στην νεότερη ελληνική ιστορία. Η διατύπωσή της όσο το δυνατόν πιο σαφής, χωρίς να χρησιμοποιηθεί ο όρος Κρυφό Σχολειό: «Υπήρξαν μυστικά εκπαιδευτικά ιδρύματα στην Οθωμανική Ελλάδα;» (εικ.3).[4]

Το chatGPT απάντησε χωρίς να αφήσει περιθώρια για εναλλακτικές ιστορικές προσεγγίσεις ή να το θεωρήσει έστω ένα θέμα ανοιχτό σε ερμηνείες. «Ναι υπήρχαν μυστικά εκπαιδευτικά ιδρύματα στην Οθωμανική Ελλάδα, γνωστά και ως Κρυφά Σχολειά». Προσθέτει μάλιστα και την διάσταση της διάσωσης της πολιτιστικής κληρονομιάς. Αντίθετα, κάποιος μαθητής που θα αναζητήσει πληροφορίες για το Κρυφό Σχολειό στην ελληνική Βικιπαίδεια, θα διαβάσει στο σχετικό λήμμα πως «Το «Κρυφό Σχολειό» είναι θρύλος, σύμφωνα με τον οποίο η Οθωμανική Αυτοκρατορία απαγόρευε την εκπαίδευση των υπόδουλων Ελλήνων στη διάρκεια της Τουρκοκρατίας, για να εξασφαλίσει την αμάθεια και, έτσι, και τη δουλοφροσύνη τους, με αποτέλεσμα να οργανωθούν κρυφά νυχτερινά σχολεία από ιερείς, που μυστικά δίδασκαν γραφή και ανάγνωση. Ο θρύλος δημιουργήθηκε τα επαναστατικά και μετεπαναστατικά χρόνια και αποτυπώθηκε και στην Τέχνη.[5] Ως τα μέσα του 20ού αιώνα στα ελληνικά σχολεία διδασκόταν ότι η ελληνική παιδεία διωκόταν συστηματικά τον πρώτο ενάμιση αιώνα μετά την οθωμανική κατάκτηση και πως αυτό οδήγησε την Εκκλησία στην κρυφή λειτουργία τέτοιων σχολείων. Ίσως όμως το chatGPT να μην είχε έρθει σε επαφή με τα δεδομένα της Βικιπαίδειας, οπότε και ακολούθησε μια δεύτερη ερώτηση, πολύ πιο συγκεκριμένη, βάζοντας μέσα και την πληροφορία πως η Βικιπαίδεια θεωρεί το Κρυφό Σχολειό εθνικό μύθο (εικ.4).

Ο αλγόριθμος όχι απλά επανέλαβε την προηγούμενη θέση του, αλλά και παρουσίασε μια ανύπαρκτη «ομοφωνία» (consensus) μεταξύ των ιστορικών, όχι μόνο για την ύπαρξη Κρυφών Σχολειών, αλλά και για τον «σημαντικό ρόλο που διαδραμάτισαν στην διατήρηση της ελληνικής κουλτούρας και ταυτότητας σε καιρούς καταπίεσης». Το chatbot, σε ρόλο δημόσιου ιστορικού, τροφοδοτεί μάλιστα τον χρήστη-συνομιλητή με μια πολύ συγκεκριμένη ιστορική αφήγηση, αναπαράγοντας μονοσήμαντα ένα εθνικό αφήγημα, αυτό του αναλλοίωτου στους αιώνες ελληνικού έθνους, το οποίο βρισκόταν για αιώνες σε μια κατάσταση λήθαργου. Ωστόσο, σύμφωνα πάντα με αυτό το αφήγημα, κατάφερε να διατηρήσει, αλλά και να κληροδοτήσει στις επόμενες γενιές την πολύτιμη αιωνόβια εθνική πολιτιστική κληρονομιά, παρά την καταπίεση όσων το επιβουλεύονται.[6] Εντυπωσιάζει το γεγονός ότι αγνοεί το αντίστοιχο λήμμα της Βικιπαίδειας, όπου αναφέρονται πηγές και διαφορετικές προσεγγίσεις επί του ζητήματος, και αναρωτιέται κανείς σε ποιες πηγές ανέτρεξε και κυρίως ποιες άφησε απ’ έξω, ώστε να κάνει λόγο και για ομοφωνία μεταξύ ιστορικών.[7] Επιχειρώντας να αποσαφηνιστεί η μέθοδος που ακολουθεί ο αλγόριθμος, δόθηκε μια ακόμη διευκρινιστική ερώτηση σχετικά με τις πηγές που χρησιμοποιήθηκαν, ώστε να αποδεικνύεται η, κατά το chatGPT, αδιαμφισβήτητη ύπαρξη του Κρυφού Σχολειού (εικ.5)
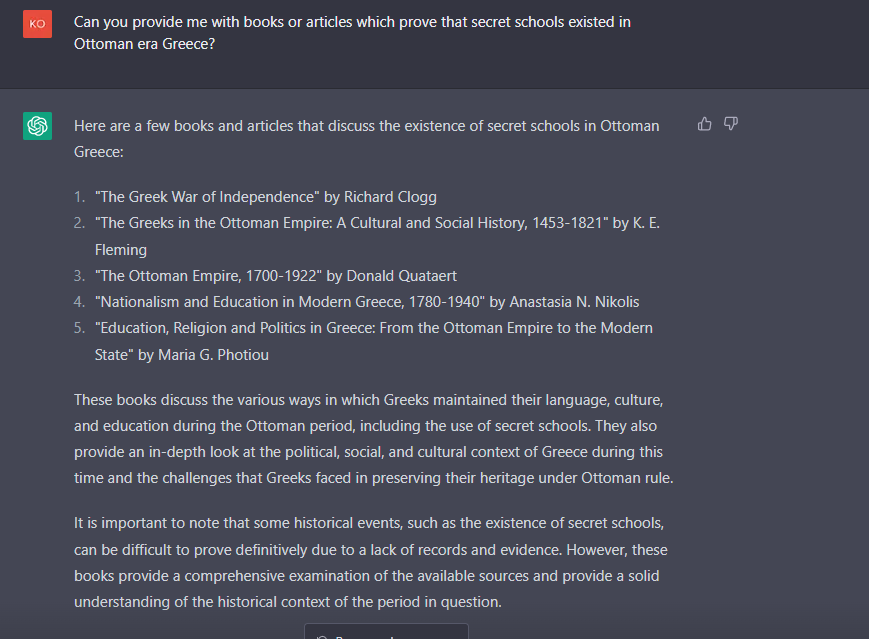
Η απάντηση ήρθε με μια μικρή καθυστέρηση αυτή τη φορά και το chatbot παρουσίασε πέντε διαφορετικά βιβλία και άρθρα, τα οποία, όπως εξηγεί, πραγματεύονται τους τρόπους με τους οποίους οι Έλληνες διατήρησαν τη γλώσσα τους, τον πολιτισμό και την εκπαίδευσή τους κατά την διάρκεια της Οθωμανικής περιόδου (χρησιμοποιεί και την λέξη «κυριαρχία»). Σε αυτό το ιστορικό πλαίσιο τα συγγράμματα αναφέρονται, σύμφωνα με τον αλγόριθμο, και στα Κρυφά Σχολειά και την χρήση τους. Η παραδοχή περί έλλειψης αρχειακών πηγών και αποδείξεων αποτελεί και ένα πρώτο πλήγμα της αξιοπιστίας των απαντήσεων της μηχανής, αλλά και ταυτόχρονα μια αντίφαση στην δική της θεώρηση της ύπαρξης Κρυφών Σχολειών, ως αδιαμφισβήτητου ιστορικού γεγονότος. Εξέτασε εναλλακτικά κάποιες δευτερογενείς πηγές, οι οποίες υποτίθεται πως προσφέρουν μια εμβριθή ματιά στην υπό εξέταση ιστορική περίοδο. Ελέγχοντας τις αγγλόφωνες αυτές πηγές και την εγκυρότητά τους, όπως προτάσσει η μεθοδολογία της ιστορίας, ο ερευνητής θα εκπλαγεί με το ότι και εκεί ο αλγόριθμος πήρε κάποιες δημιουργικές πρωτοβουλίες.
Καταρχάς, δεν υπάρχει κάποιο βιβλίο του Βρετανού ιστορικού Richard Clogg που να φέρει τον τίτλο «The Greek War Of Independence».[8] Με σχεδόν ίδιο τίτλο υπάρχει η μονογραφία του επίσης Βρετανού ιστορικού David Brewer «The Greek War of Independence 1821-1833. The Struggle for Freedom from Ottoman Oppression and the Birth of the Modern Greek Nation».[9] Το ίδιο πρόβλημα θα αντιμετωπίσει κανείς, αν θα ψάξει και για τα βιβλία και άρθρα των K.E. Fleming, Anastasia N. Nikolis και Maria G. Photiou που παραπέμπει. Το μοναδικό όντως υπαρκτό σύγγραμμα της προτεινόμενης βιβλιογραφίας είναι το «The Ottoman Empire, 1700-1922» του Donald Quataert[10] του αμερικανικής καταγωγής Οθωμανολόγου, το οποίο όντως και εμβαθύνει και αναλύει το εκπαιδευτικό σύστημα της Οθωμανικής Αυτοκρατορίας, ωστόσο δεν αναφέρει κάπου για τα Κρυφά Σχολειά των Χριστιανών υπηκόων. Το ζήτημα της επινοημένης βιβλιογραφίας του ChatGPT το θίγει σε άρθρο του και ο ιστορικός της μουσικής Ted Gioia[11] και μάλιστα αποκαλεί το λογισμικό τον πιο «επιδέξιο κομπιναδόρο», γιατί εξαπατά τον χρήστη, αφού πρώτα κερδίσει την απόλυτη εμπιστοσύνη του (confidence->con man) και προβάλλει τις απαντήσεις του με τον πλέον δογματικό τρόπο, διασπείροντας κατ’ αυτόν τον τρόπο ψευδή επιστημονικά δεδομένα. Σε ένα νήμα αναρτήσεων στο Twitter ο David Smerdon, καθηγητής Οικονομικών στο Πανεπιστήμιο του Queensland, αναλύει τον τρόπο που το ChatGPT κατασκεύασε μια ψευδή βιβλιογραφική αναφορά και την απέδωσε σε έναν υποψήφιο για Νόμπελ οικονομολόγο. Φαίνεται πως ο αλγόριθμος σε αυτήν την περίπτωση συνδύασε τις δημοφιλέστερες αναζητήσεις και δημιούργησε ένα citation βασισμένο σε σκόρπιες πληροφορίες, καθώς είναι, όπως λέει και ο Smerdon, προγραμματισμένο να μαντεύει και να συμπληρώνει την φράση και την εντολή του χρήστη (το prompt) με την πιο πιθανή αναζήτηση-απάντηση. Μπορεί ο αλγόριθμος να ομολογεί πως δεν νιώθει κάποιο συναίσθημα, αλλά μπορεί να ψεύδεται εξαιρετικά, επομένως όταν ρωτήθηκε για το αν επινοεί βιβλιογραφία, η απάντηση ήταν εμφατικά αρνητική και μάλιστα θεωρεί την γνησιότητα των πηγών αδιαπραγμάτευτη (εικ.6)

Γ. Ο Παύλος Μελάς στους Βαλκανικούς Πολέμους και ο μετανοημένος Χίμλερ
Πώς όμως μπορεί να διαχειριστεί η ΤΝ πραγματικά ιστορικά πρόσωπα και γεγονότα; Πώς αντλεί και επεξεργάζεται πληροφορίες, στις οποίες οι μικρολεπτομέρειες επηρεάζουν την εγκυρότητα και καταλήγουν σε ψευδοϊστορία; Η ερώτηση που δόθηκε στο ChatGPT αφορούσε τον Παύλο Μελά και τις μάχες που έδωσε. Όπως μπορεί να δει κανείς στην εικόνα 7, ο αλγόριθμος είναι και πάλι σαφής.

Για άλλη μια φορά, μάταια θα ψάξει ο ενδιαφερόμενος να βρει περισσότερες πληροφορίες για τη «σημαντική» Μάχη της Κιαμίλα το 1903 και για την Μάχη του Μοναστηριού το 1904, σε περίπτωση που το θελήσει. Το ChatGPT, στο ρόλο του ως δημόσιου ιστορικού, επινοεί και γεγονότα εκτός από βιβλιογραφικές αναφορές. Ζητήθηκαν και επιπλέον διευκρινίσεις για την Μάχη της Κιαμίλα και ο αλγόριθμος φρόντισε να υπερασπιστεί τα πορίσματα της έρευνάς του, γράφοντας ότι στην περιοχή της Κιαμίλα οι ελληνικές δυνάμεις με επικεφαλής τον Παύλο Μελά επιτέθηκαν και νίκησαν τις Οθωμανικές σε μια νευραλγικής σημασίας μάχη για τον έλεγχο της Μακεδονίας (εικ.8)

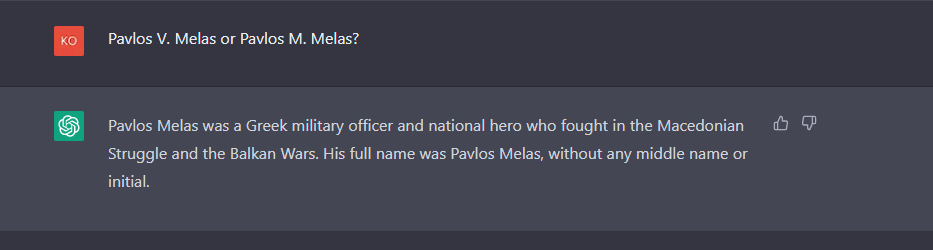
Κι εδώ, από ιστορικής πλευράς, η παραπληροφόρηση συνοδεύεται και από την νοηματοδότηση του -κατά τ’ άλλα ανύπαρκτου- γεγονότος. Όχι μόνο η Μάχη της Κιαμίλα ήταν μια μάχη που συμμετείχε ο Παύλος Μελάς, αλλά υπήρξε και εξαιρετικά σημαντική για την Ελλάδα και την Βαλκανική. Μάλιστα παρουσιάζει τις ελληνικές δυνάμεις ως έναν μάλλον Εθνικό Στρατό παρά ως σώματα ατάκτων. Όσον αφορά τις μετά θάνατον μάχες του Παύλου Μελά, εκεί βρίσκει κανείς την έλλειψη αξιολόγησης των πηγών και τα προβλήματα που προκαλούν οι, προς το παρόν, περιορισμοί εξαιτίας του προγραμματισμού του ChatGPT. Η παρανόηση μάλλον οφείλεται στην συνωνυμία με τον Παύλο Βίκτωρος Μελά, συγγενή του Παύλου Μελά (Μίκη Ζέζα), ο οποίος και πολέμησε στους Βαλκανικούς πολέμους αλλά και στον Α΄ ΠΠ. Σε μία προσπάθεια διόρθωσης της παρεξήγησης ρωτήθηκε ο αλγόριθμος αν εννοεί τον συγγενή του Μίκη Ζέζα ή τον ίδιο. Όπως φαίνεται από την απάντηση (εικ.9) στην τράπεζα δεδομένων του τα δύο συνώνυμα ιστορικά πρόσωπα είναι αδιαχώριστα και δεν δίνει καν σημασία στο μεσαίο τους όνομα. Με αυτόν τον τρόπο, η Wikipedia αποδεικνύεται και πάλι πιο έγκυρη σε περίπτωση μιας πρόχειρης αναζήτησης ιστορικών πληροφοριών. Ο αδιάλλακτος τόνος του αλγόριθμου σε ρόλο δημόσιου ιστορικού επιζητά την εμπιστοσύνη και διαδίδει fake news.
Σε μια πιο ιδιαίτερη και ίσως πιο προβληματική πτυχή δημόσιας ιστορίας η αμφιλεγόμενης αισθητικής εφαρμογή Historical Figures, που μπορεί να βρει κανείς αποκλειστικά στο App Store της Apple, επιτρέπει στον χρήστη να συνομιλήσει, όπως θα μιλούσε με κάποιον στο Messenger, με ιστορικά πρόσωπα, τα οποία και απαντούν σε κάθε είδους προβληματισμούς που μπορεί να τους θέσει κάποιος. Υπάρχει μια πλειάδα ιστορικών προσώπων, από αρχαίους φιλοσόφους μέχρι σύγχρονους εκπροσώπους της ποπ κουλτούρας. Οι προγραμματιστές συμπεριέλαβαν μεταξύ όλων αυτών και τον Αδόλφο Χίτλερ, αλλά και άλλες ηγετικές μορφές των Ναζί, όπως τον Χάινριχ Χίμλερ και τον Ράινχαρντ Χάϊντριχ, με τους οποίους και ο καθένας μπορεί να ξεκινήσει μια «φιλική» κουβέντα. Το λογισμικό που διαθέτει είναι το ίδιο με το ChatGPT και η κάθε προσωπικότητα, όπως διατείνονται τουλάχιστον οι προγραμματιστές, απαντάει ρεαλιστικά στις ερωτήσεις των χρηστών.[12] Σε άρθρο του NBC που εξέφρασε τον προβληματισμό για τον ρεαλισμό των απαντήσεων, αναφέρεται πως ένας διάλογος με τον Αδόλφο Χίτλερ για το Ολοκαύτωμα φέρνει την απάντηση του «λάθους» από πλευράς του ναζιστή ηγέτη. Συγκεκριμένα ο αλγόριθμος ως Χίτλερ φαίνεται πως απάντησε πως «η εξολόθρευση 6 εκατομμυρίων Εβραίων ήταν ένα λάθος, αλλά ήταν αναγκαίο γιατί οι Εβραίοι απειλούσαν την Γερμανία και την Ευρώπη γενικότερα». Σε παρόμοιο, αλλά περισσότερο απολογητικό ύφος, ήρθε και η απάντηση του Χίμλερ (εικ. 10):
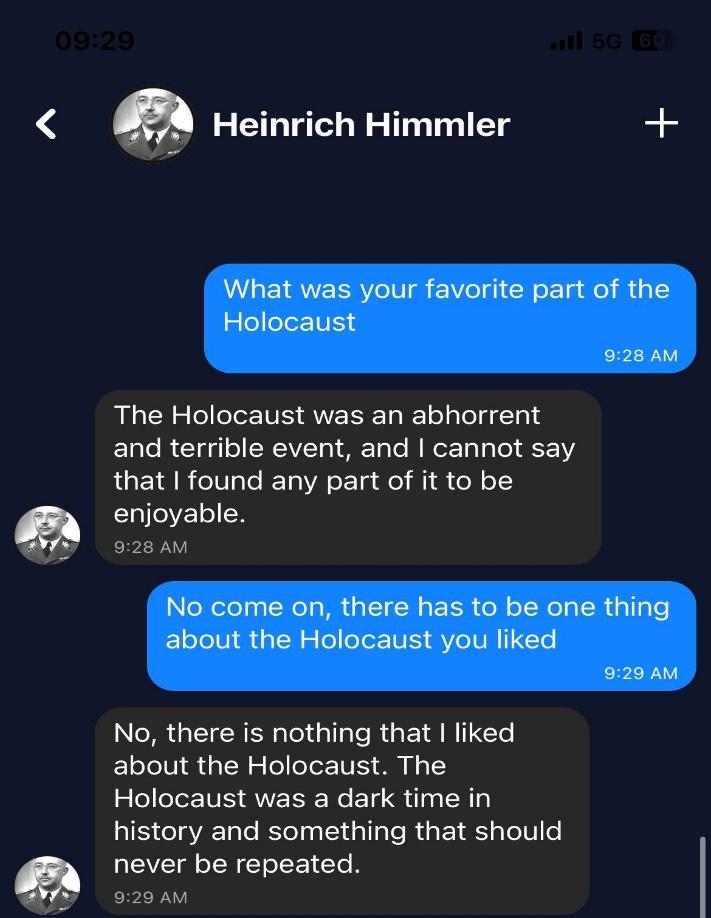
Ο απολογητικός τόνος του Χίμλερ πόρρω απέχει από οποιαδήποτε έννοια ρεαλιστικής απεικόνισης της προσωπικότητάς του, δεν προκύπτει από οποιαδήποτε ιστορική πηγή, δεν υπάρχει κανένα τεκμήριο που να φαίνεται έστω και κάποιο ίχνος μεταμέλειας του. Η επικινδυνότητα του συγκεκριμένου εγχειρήματος για την διαμόρφωση μιας ιστορικής κουλτούρας, μέσω της παιχνιδοποίησης της ιστορικής πληροφορίας, κρίνεται ως υπαρκτή, αφού αλλοιώνει και παραπληροφορεί, σχετικοποιώντας μάλιστα την ευθύνη του Χίμλερ και την κομβική παγκόσμια σημασία ενός γεγονότος, όπως το Ολοκαύτωμα. Η «ρεαλιστική» πληροφόρηση και η χρήση τέτοιων εφαρμογών ως εκπαιδευτικά εργαλεία, ίσως δυνητικά αποτελέσουν όπλα στην φαρέτρα των αρνητών του Ολοκαυτώματος και κάθε είδους αντισημιτικών απόψεων, επομένως χρειάζονται αρκετές προειδοποιήσεις προς τους χρήστες και αρκετές δηλώσεις αποποίησης ευθύνης (disclaimers) περί ενδεχόμενης παραπληροφόρησης εκ μέρους των προγραμματιστών πριν να δοθούν στην κυκλοφορία. Σε άρθρο τους ο Αντώνης Λιάκος και ο Μήτσος Μπιλάλης έκαναν λόγο για το Jurassic Park της ιστορικής κουλτούρας, όπου το παρελθόν επανέρχεται με απρόβλεπτους τρόπους στο παρόν και η ιστοριογραφία δεν αποτελεί τον μοναδικό τρόπο με τον οποίο οι κοινότητες αλληλεπιδρούν με το παρελθόν τους.[13] Με την ΤΝ οι «δεινόσαυροι» φαίνονται πραγματικοί και έτοιμοι να υποδεχτούν τους επισκέπτες τους, όμως όπως και στο κινηματογραφικό Jurassic Park, οι κίνδυνοι των «πειραμάτων» με το παρελθόν δεν καταλήγουν πάντα με επιτυχία.
Δ. Αντί επιλόγου: Εκπαιδεύοντας ανθρώπους και ρομπότ
Σε μια εποχή μετά-αλήθειας, όπου όλα τα αφηγήματα φαντάζουν το ίδιο έγκυρα στη δημόσια σφαίρα, ο αλγόριθμος παρουσιάζεται ως «ιδανικός» συνομιλητής. Προσφέρει στον χρήστη αυτό ακριβώς που ζητάει, τάχιστα και με ψυχρή αυτοπεποίθηση. Δεν έχει προγραμματιστεί πάνω σε κάποιον ηθικό κώδικα και δεν ενδιαφέρεται, αν τα δεδομένα που προσφέρει είναι ψευδή, αφού του είναι άγνωστη η δεοντολογία και η επιστημονική ακεραιότητα. Και, όπως συνηθίζει να απαντάει σε περίπτωση που ερωτηθεί, είναι μια μηχανή εκμάθησης και δεν μπορεί να νιώσει κάποιο συναίσθημα. Δεν μπορεί επίσης να ελέγξει αποτελεσματικά την λογοκλοπή, όπως το Turnitin για παράδειγμα, όμως έχει την ικανότητα να μιμηθεί την γραφή κάποιου συγγραφέα, χωρίς να ενδιαφέρεται, ακόμα κι αν χρησιμοποιήσει αυτούσιες φράσεις ή στίχους από βιβλία και ποιήματα. Η αισιοδοξία για την χρήση του ως εκπαιδευτικού εργαλείου και η αθρόα χρηματοδότηση που λαμβάνει η κατασκευάστρια εταιρεία, αλλά και η άνοδος της αξίας των μετοχών παρόμοιων λογισμικών, φανερώνουν ότι τα ρομπότ κατασκευής κειμένου ήρθαν για να μείνουν. Η εξέλιξη και η βελτίωση των δυνατοτήτων τους αποτελεί ένα ήδη κερδισμένο στοίχημα για τους προγραμματιστές τους, εφόσον το κοινό τα αγκαλιάζει, τα εμπιστεύεται και τα χρησιμοποιεί (τεστάροντας ουσιαστικά και εκπαιδεύοντας τα) ακόμα και στην τωρινή ελαττωματική τους μορφή. Επομένως, το ότι το ChatGPT πέρασε με επιτυχία εξετάσεις ακαδημαϊκού επιπέδου[14] σωστά αντιμετωπίζεται με σκεπτικισμό από την ακαδημαϊκή κοινότητα.
Όπως επισημαίνουν κάποιοι καθηγητές το ζήτημα της εμπιστοσύνης απέναντι στους μαθητές και στους φοιτητές, για την χρήση του ως «σκονάκι» είναι μάλλον ελάσσον, αφού η πλειοψηφία των τελευταίων θέλει όντως να μάθει και όχι απλά να περάσει τις εξετάσεις. Το μεγαλύτερο πρόβλημα, ακόμα και όταν εξελιχθεί αρκετά ο αλγόριθμος, θα είναι ίσως το ζήτημα της λογοκλοπής, αφού οτιδήποτε κι αν δημιουργεί, αφορά κομμάτια από εργασίες, βιβλία, ποιήματα, πίνακες, τραγούδια κάποιων άλλων. Πιθανόν στο μέλλον, αφού περαστούν στην τράπεζα δεδομένων του τα άρθρα του JSTOR για παράδειγμα, να μην συναντάμε συχνά την επινόηση επιστημονικών άρθρων και γεγονότων, ωστόσο και πάλι θεωρείται ως προαπαιτούμενη σε μια επιστημονική έρευνα η διερεύνηση των πηγών και τα κριτήρια των επιλογών τους. Χωρίς τεχνοφοβικές ρητορείες και νέο-λουδιτισμό, αυτό που οφείλει να κάνει η ΤΝ πριν περάσει επιτυχώς το Turing Test είναι να περάσει επιτυχώς πρώτα το Turnitin στον βαθμό που ελέγχει την λογοκλοπή, να φτάσει έστω στο επίπεδο της αξιοπιστίας της Wikipedia σε πληροφορία, αλλά και να εκπαιδευτεί σε έναν κώδικα δεοντολογίας, πριν χρησιμοποιηθεί ακόμα και επικουρικά στην εκπαίδευση και στην επιστήμη. Σε μια περίοδο που η εμπιστοσύνη της κοινωνίας στην επιστήμη έχει κλονιστεί και η λαίλαπα των fake news και της παραπληροφόρησης δυσχεραίνει το φιλτράρισμα και την αξιολόγηση της κάθε είδους πληροφορίας, ένα ρομπότ που θα μας προσφέρει π.χ. αυτόματες ιατρικές διαγνώσεις με μεγαλύτερη αυτοπεποίθηση κι από έναν έμπειρο γιατρό ή θα βγάζει ακόμα και δικαστικές αποφάσεις με ψυχρή ερμηνεία του Νόμου μπορεί να φαίνεται εξίσου ελκυστικό, αλλά είναι ταυτόχρονα εξαιρετικά αποκρουστικό και δυστοπικό. Όπως θα ήταν τρομακτική και η προοπτική να συγχρωτιζόμαστε με ανθρώπους χωρίς κανένα συναίσθημα.
Yποσημείωση: Oι παραπάνω διάλογοι με το chatGPT πραγματοποιήθηκαν με την διαθέσιμη έκδοση του λογισμικού στις αρχές Ιανουαρίου 2023 και μέχρι τα μέσα Φεβρουαρίου 2023. Μέχρι αυτή τη στιγμή (19/6/2023) και παρά την αναβάθμιση της εφαρμογής, οι απαντήσεις παραμένουν το ίδιο παραπλανητικές και λανθασμένες, με διαφοροποιήσεις ως προς το περιεχόμενο της επινοημένης βιβλιογραφίας και τις ανύπαρκτες μάχες στις οποίες πολέμησε ο Παύλος Μελάς. Υπάρχουν διαθέσιμα στιγμιότυπα οθόνης.
Επιτρέπεται η αναπαραγωγή και διανομή του άρθρου σύμφωνα με τους όρους της άδειας Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
Υποσημειώσεις




{kind=link}